如果你觉得这篇文章能给你带来收获,请关注我公众号:
这篇文章主要给大家介绍max_result_window参数及其对性能影响。
Part1 背景描述
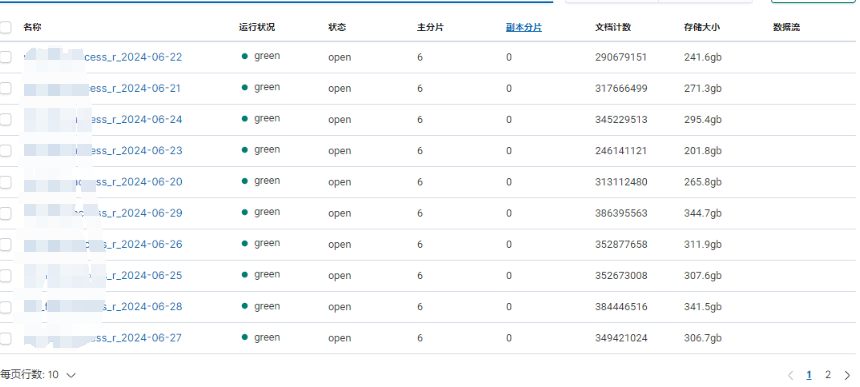
当前某个业务xxxdb单个索引值较大,每日单个索引大小在二三百G,当前索引保留15天,如果拉取一个15天的范围周期,会查询到几个T的数据量,并且该索引未做副本,这种大查询会导致ES负载较高,严重影响性能。
单日索引大小
检查发现xxx_access_xxx_xxx 索引使用的索引模版xxx_xxx_access_xxx_template 有个参数max_result_window 比较异常,设置值较大。
-- 查询xxx_xxxx_access_xxx_template索引模版信息
GET /_template/xxx_xxx_access_xxx_template
-- 上述命令执行结果如下:
{
"xxx_xxx_access_xxx_template" : {
"order" : 8,
"index_patterns" : [
"xxx_xxx_access_xxx_*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "5d_cold_15d_delete_policy"
},
"refresh_interval" : "30s",
"number_of_shards" : "10",
"translog" : {
"sync_interval" : "60s"
},
"merge" : {
"scheduler" : {
"max_thread_count" : "1"
},
"policy" : {
"max_merged_segment" : "500m"
}
},
"max_result_window" : "1000000",
"analysis" : {
"analyzer" : {
"comma_analyzer" : {
"filter" : [
"lowercase"
],
"char_filter" : [
"replace_comma"
],
"type" : "custom",
"tokenizer" : "standard"
},
"file_analyzer" : {
"filter" : [
"lowercase"
],
"char_filter" : [
"file_sep"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"char_filter" : {
"file_sep" : {
"type" : "mapping",
"mappings" : [
"/ => ' '",
". => ' '"
]
},
"replace_comma" : {
"type" : "mapping",
"mappings" : [
". => ' '",
", => ' '",
"# => ' '",
"$ => ' '",
"% => ' '",
"' => ' '",
"( => ' '",
") => ' '",
"* => ' '",
"+ => ' '",
"- => ' '",
"/ => ' '",
": => ' '",
"; => ' '",
"< => ' '",
"= => ' '",
"> => ' '",
"? => ' '",
"@ => ' '",
"[ => ' '",
"] => ' '",
"^ => ' '",
"{ => ' '",
"} => ' '",
"~ => ' '",
"` => ' '",
"| => ' '",
"& => ' '",
"! => ' '",
"\" => ' '",
"_ => ' '"
]
}
}
},
"number_of_replicas" : "0"
}
},
"mappings" : {
"properties" : {
"schema" : {
"type" : "text"
},
"netSendTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"checkLengthTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"routeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"type" : {
"type" : "text"
},
"databaseTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"resultSetSize" : {
"ignore_malformed" : true,
"type" : "long"
},
"sql" : {
"analyzer" : "comma_analyzer",
"type" : "text"
},
"minNodeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"dbExeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"startTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlRows" : {
"ignore_malformed" : true,
"type" : "long"
},
"mergeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlStartTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"dataNodeNum" : {
"ignore_malformed" : true,
"type" : "long"
},
"funcDbTime" : {
"ignore_malformed" : true,
"type" : "integer"
},
"dataNode" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"maxReceiveNodeResultsTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"MaxNodeTime" : {
"ignore_malformed" : true,
"type" : "integer"
},
"allTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"funcRedisTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"selectRowTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"fddbTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlType" : {
"ignore_malformed" : true,
"type" : "long"
},
"calcTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"endTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"minReceiveNodeResultsTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"extern1" : {
"ignore_malformed" : true,
"type" : "long"
},
"user" : {
"type" : "text"
},
"executeTime" : {
"ignore_malformed" : true,
"type" : "long"
}
}
},
"aliases" : { }
}
}
1 max_result_window 解释
通过上面命令可以看到 max_result_window 值设置过大,当前设置为 1000000 (一百万)。
max_result_window 这个参数是什么意思,是用来做什么的呢?
max_result_window 是 Elasticsearch 中的一个参数,它决定了可以从单个查询中请求的最大结果窗口的大小。换句话说,它控制了可以通过 from 和 size 参数获取的最大文档数量。这对于防止过度内存使用和性能问题非常重要,因为请求大量数据会消耗大量内存并影响集群性能。
示例:
如果有一个索引并希望从该索引中检索文档,可以使用 from 和 size 参数来控制分页:
GET /index_name/_search
{
"from": 0,
"size": 100
}
这将返回前 100 个文档。from 参数指定要跳过的文档数,size 参数指定要返回的文档数。
但如果尝试执行如下操作:
GET /index_name/_search
{
"from": 10000,
"size": 100
}
在默认配置下,这将返回一个错误,因为 from + size 超过了 max_result_window 的限制。
如果希望更改更大的结果窗口,可以在索引中调整 max_result_window 参数,比如:
PUT /index_name/_settings
{
"index": {
"max_result_window": 50000
}
}
这将 max_result_window 设置为 50,000。
在 Elasticsearch 7.12.1 版本中,max_result_window 的默认值是 10,000。这意味着默认情况下,您可以请求的结果窗口最大为 10,000 个文档。如果尝试请求超过这个限制的结果窗口,Elasticsearch 会返回一个错误。
max_result_window 支持的最大返回数是 2^31-1,也就是2147483647,生产不建议对 max_result_window 设置过大的值,过大的max_result_window值会对ES带来性能问题,可能会因为值设置过大导致ES内存问题和性能下降。
可以通过设置 from 和 size 参数可以进行分页查询。例如:from=num_a, size=num_b,则获取的结果是从第 num_a + 1 条到第 num_a + num_b 条数据。
2 参数调整
根据对上面max_result_window 参数的分析,计划对 max_result_window值进行调整,将其调整为默认大小。
最简单的方法是通过修改索引模版json信息,将该参数从索引模版删除,调整为默认值,执行如下修改命令:
PUT /_template/xxx_xxx_access_xxx_template
{
"order" : 8,
"index_patterns" : [
"xxx_xxx_access_xxx_*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "5d_cold_15d_delete_policy"
},
"refresh_interval" : "30s",
"number_of_shards" : "10",
"translog" : {
"sync_interval" : "60s"
},
"merge" : {
"scheduler" : {
"max_thread_count" : "1"
},
"policy" : {
"max_merged_segment" : "500m"
}
},
"analysis" : {
"analyzer" : {
"comma_analyzer" : {
"filter" : [
"lowercase"
],
"char_filter" : [
"replace_comma"
],
"type" : "custom",
"tokenizer" : "standard"
},
"file_analyzer" : {
"filter" : [
"lowercase"
],
"char_filter" : [
"file_sep"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"char_filter" : {
"file_sep" : {
"type" : "mapping",
"mappings" : [
"/ => ' '",
". => ' '"
]
},
"replace_comma" : {
"type" : "mapping",
"mappings" : [
". => ' '",
", => ' '",
"# => ' '",
"$ => ' '",
"% => ' '",
"' => ' '",
"( => ' '",
") => ' '",
"* => ' '",
"+ => ' '",
"- => ' '",
"/ => ' '",
": => ' '",
"; => ' '",
"< => ' '",
"= => ' '",
"> => ' '",
"? => ' '",
"@ => ' '",
"[ => ' '",
"] => ' '",
"^ => ' '",
"{ => ' '",
"} => ' '",
"~ => ' '",
"` => ' '",
"| => ' '",
"& => ' '",
"! => ' '",
"\" => ' '",
"_ => ' '"
]
}
}
},
"number_of_replicas" : "0"
}
},
"mappings" : {
"properties" : {
"schema" : {
"type" : "text"
},
"netSendTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"checkLengthTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"routeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"type" : {
"type" : "text"
},
"databaseTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"resultSetSize" : {
"ignore_malformed" : true,
"type" : "long"
},
"sql" : {
"analyzer" : "comma_analyzer",
"type" : "text"
},
"minNodeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"dbExeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"startTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlRows" : {
"ignore_malformed" : true,
"type" : "long"
},
"mergeTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlStartTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"dataNodeNum" : {
"ignore_malformed" : true,
"type" : "long"
},
"funcDbTime" : {
"ignore_malformed" : true,
"type" : "integer"
},
"dataNode" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"maxReceiveNodeResultsTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"MaxNodeTime" : {
"ignore_malformed" : true,
"type" : "integer"
},
"allTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"funcRedisTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"selectRowTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"fddbTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"sqlType" : {
"ignore_malformed" : true,
"type" : "long"
},
"calcTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"endTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"minReceiveNodeResultsTime" : {
"ignore_malformed" : true,
"type" : "long"
},
"extern1" : {
"ignore_malformed" : true,
"type" : "long"
},
"user" : {
"type" : "text"
},
"executeTime" : {
"ignore_malformed" : true,
"type" : "long"
}
}
},
"aliases" : { }
}
除了以上方法,还可以通过使用 PUT Template API在操作系统上执行。 今天带大家分享了max_result_window参数含义,后续将会给大家带来更多分享。